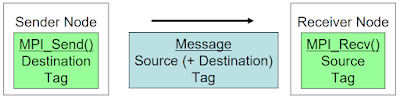
High performance network adapters are designed to provide fast and efficient data transfer between servers, storage systems, and other devices in a data center or high-performance computing environment. They typically offer advanced features such as high bandwidth, low latency, RDMA support, and offload capabilities for tasks such as encryption and compression. These adapters are often used in high-performance computing, cloud computing, and data center environments to support large-scale workloads and high-speed data transfer. Some examples of high-performance network adapters include:
- Mellanox ConnectX-6 and ConnectX-6 Dx
- Intel Ethernet Converged Network Adapter X710 and X722
- Broadcom BCM957810A1008G Network Adapter
- QLogic QL45212HLCU-CK Ethernet Adapter
- Solarflare XtremeScale X2522/X2541 Ethernet Adapter
- Chelsio T6 and T6E-CR Unified Wire Adapters
High-performance network adapters typically use specialized protocols that are designed to provide low-latency and high-bandwidth communication between systems. Some examples of these protocols include:
- Remote Direct Memory Access (RDMA): A protocol that allows data to be transferred directly between the memory of one system and another, without involving the CPU of either system.
- RoCE (RDMA over Converged Ethernet): An extension of RDMA that allows RDMA traffic to be carried over Ethernet networks.
- iWARP: A protocol that provides RDMA capabilities over standard TCP/IP networks.
- InfiniBand: A high-speed interconnect technology that provides extremely low-latency and high-bandwidth communication between systems.
These protocols are typically used in high-performance computing (HPC) environments, where low-latency and high-bandwidth communication is critical for achieving maximum performance. They are also used in other applications that require high-speed data transfer, such as machine learning, data analytics, and high-performance storage systems. Some examples of adapter features include:
- Advanced offloading capabilities: High-performance adapters can offload CPU-intensive tasks such as packet processing, encryption/decryption, and compression/decompression, freeing up server resources for other tasks.
- Low latency: Many high-performance adapters are designed to minimize latency, which is especially important for applications that require fast response times, such as high-frequency trading, real-time analytics, and scientific computing.
- Scalability: Some adapters support features such as RDMA and SR-IOV, which allow multiple virtual machines to share a single adapter while maintaining high performance and low latency.
- Security: Many high-performance adapters have hardware-based security features such as secure boot, secure firmware updates, and hardware-based encryption/decryption, which can help protect against attacks and data breaches.
- Management and monitoring: High-performance adapters often come with tools for monitoring and managing network traffic, analyzing performance, and troubleshooting issues.
A network adapter, also known as a network interface card (NIC), is a hardware component that allows a computer or other device to connect to a network. It typically includes a connector for a cable or antenna, as well as the necessary electronics to transmit and receive data over the network. Network adapters can be internal, installed inside the computer or device, or external, connected via USB or other ports. They are used for wired or wireless connections and support different types of networks such as Ethernet, WiFi, Bluetooth, and cellular networks.
 |
| source |
- IB: used for the front-end storage network in the DPC scenario.
- RoCE: used for the back-end storage network.
- TCP/IP: used for service network.
- Intel Ethernet Converged Network Adapter X520-DA2: This is a 10 Gigabit Ethernet adapter that is designed for use in data center environments. It supports both copper and fiber connections and is known for its high performance and reliability.
- Mellanox ConnectX-4 Lx EN: This is another 10 Gigabit Ethernet adapter that is designed for use in data centers. It supports both copper and fiber connections and is known for its low latency and high throughput.
- Broadcom BCM57416 NetXtreme-E: This is a 25 Gigabit Ethernet adapter that is designed for use in data centers. It supports both copper and fiber connections and is known for its high performance and reliability.
- Emulex LPe1605A: This is a 16 Gbps Fibre Channel host bus adapter (HBA) that is designed for use in storage area networks (SANs). It supports both N_Port ID Virtualization (NPIV) and N_Port Virtualization (NPV) and is known for its high performance and reliability.
- IBM Power Systems: These servers are designed for high-performance computing and big data workloads, and are based on the Power architecture. They support IBM's AIX, IBM i, and Linux operating systems.
- IBM System x: These servers are designed for general-purpose computing and are based on the x86 architecture. They support a wide range of operating systems, including Windows and Linux.
- IBM System z: These servers are designed for mainframe computing and support IBM's z/OS and z/VM operating systems.
- IBM BladeCenter: These servers are designed for blade server environments and support a wide range of operating systems, including Windows and Linux.
- IBM Storage: These servers are designed for storage and data management workloads, and support a wide range of storage protocols and operating systems.
- IBM Cloud servers: IBM Cloud servers are designed for cloud-based computing and are based on the x86 architecture. They support a wide range of operating systems, including Windows and Linux.
Emulex Corporation Device e228 is a network adapter produced by Emulex Corporation. It is an Ethernet controller, which means it is responsible for controlling the flow of data packets over an Ethernet network. The Emulex Corporation Device e228 is part of the Emulex OneConnect family of network adapters, which are designed for use in data center environments. These adapters are known for their high performance, low latency, and high throughput. They also provide advanced features such as virtualization support, Quality of Service (QoS) and offloads (TCP/IP, iSCSI, and FCoE) to improve network performance. It supports 10Gbps Ethernet and can be used in both copper and fiber connections. This adapter is typically used in servers and storage systems that require high-speed network connections and advanced features to support data-intensive applications. The "be2net" kernel driver is a Linux device driver that is used to control the Emulex Corporation Device e228 network adapter. A kernel driver is a type of low-level software that interfaces with the underlying hardware of a device, such as a network adapter. It provides an interface between the hardware and the operating system, allowing the operating system to communicate with and control the device. The "be2net" driver is specifically designed to work with the Emulex Corporation Device e228 network adapter, and is responsible for managing the flow of data packets between the device and the operating system. It provides the necessary functionality for the operating system to access the adapter's features and capabilities, such as configuring network settings, monitoring link status and performance, and offloading network processing tasks. The be2net driver is typically included with the Linux operating system and it's loaded automatically when the device is detected. It's also available as a separate package, that can be installed and configured manually.
The Mellanox Technologies MT28800 Family [ConnectX-5 Ex Virtual Function] is a network adapter produced by Mellanox Technologies. It is an Ethernet controller, which means it is responsible for controlling the flow of data packets over an Ethernet network. This adapter is part of the Mellanox ConnectX-5 Ex family of network adapters, which are designed for use in data center environments. These adapters are known for their high performance, low latency, and high throughput. They support 100 Gbps Ethernet, RoCE v2 and InfiniBand protocols and provide advanced features such as virtualization support, Quality of Service (QoS), and offloads to improve network performance. It's worth noting that the Mellanox ConnectX-5 Ex Virtual Function is a specific type of adapter that is designed to be used in virtualized environments. It allows multiple virtual machines to share a single physical adapter, thus providing better flexibility and resource utilization. This adapter is typically used in servers, storage systems, and other high-performance computing devices that require high-speed network connections and advanced features to support data-intensive applications such as big data analytics, machine learning, and high-performance computing.
- Mellanox ConnectX-5 CNA: This adapter supports both Ethernet and Fibre Channel over Ethernet (FCoE) on a single adapter, and provides high-performance, low-latency data transfer.
- Mellanox ConnectX-6 CNA: This adapter supports 100 GbE and 200 GbE speeds and provides hardware offloads for RoCE, iWARP and TCP/IP, in addition to supporting FC and FCoE protocols.
- Mellanox ConnectX-5 EN CNA: This adapter supports both Ethernet and InfiniBand protocols, providing high-performance, low-latency data transfer for data center and high-performance computing environments.
- Mellanox ConnectX-6 Lx CNA: This adapter supports 25 GbE and 50 GbE speeds, and provides hardware offloads for RoCE, iWARP, and TCP/IP, in addition to supporting FC and FCoE protocols.

 |
| source |

- InfiniBand: RDMA is considered at the beginning of the design to ensure reliable transmission at the hardware level and provide higher bandwidth and lower latency. However, the cost is high because IB NICs and switches must be supported.
- RoCE: RDMA based on Ethernet consumes less resources than iWARP and supports more features than iWARP. You can use common Ethernet switches that support RoCE NICs.
- iWARP: TCP-based RDMA network, which uses TCP to achieve reliable transmission. Compared with RoCE, on a large-scale network, a large number of TCP connections of iWARP occupy a large number of memory resources. Therefore, iWARP has higher requirements on system specifications than RoCE. You can use common Ethernet switches that support iWARP NICs.

- Low-latency: RoCE allows for very low-latency data transfer, which is critical for high-performance computing and big data analytics applications.
- High-throughput: RoCE allows for high-bandwidth data transfer, which is necessary for handling large amounts of data.
- RDMA support: RoCE is based on the RDMA protocol, which allows for direct memory access over a network, resulting in low-latency and high-bandwidth data transfer.
- Converged Ethernet: RoCE uses standard Ethernet networks and devices, making it simpler to set up and manage than traditional RDMA over Infiniband.
- Quality of Service (QoS) support: RoCE can provide Quality of Service (QoS) feature, which allows for guaranteed bandwidth and low-latency for critical applications.
- Virtualization support: RoCE can be used with virtualized environments, allowing multiple virtual machines to share a single physical adapter, thus providing better flexibility and resource utilization.


 |
| Differences between RoCE, Infiniband RDMA, and TCP/IP. |
- Protocols: HBAs support different storage protocols such as Fibre Channel (FC), Fibre Channel over Ethernet (FCoE), and iSCSI. FC and FCoE are commonly used in enterprise environments, while iSCSI is more commonly used in smaller, SMB environments. Speed: HBAs are available in different speeds, such as 8 Gb/s, 16 Gb/s, and 32 Gb/s. Higher speeds provide faster data transfer and improved performance.
- Multi-Path Support: HBAs often support multi-path I/O, which allows multiple paths to the storage devices to be used for failover and load balancing. Compatibility: HBAs are designed to work with specific operating systems, so it's important to check the compatibility of the HBA with the operating system you are using.
- Management and Monitoring: Many HBAs include management and monitoring software that allows administrators to view and configure the HBA's settings, such as Fibre Channel zoning, and to monitor the performance of the HBA and the storage devices it is connected to. Driver and Firmware: HBA's require driver and firmware to work properly, so it's important to ensure that the HBA has the latest driver and firmware updates installed.
- Vendor Support: It's important to consider the vendor support of the HBA, as well as the warranty and technical support options available, as these can be critical factors when choosing an HBA. Architecture: Some HBAs are based on ASIC (Application-Specific Integrated Circuit) while others on FPGA (Field-Programmable Gate Array) architecture, both have their own pros and cons.
- Higher core count: Power10 processors have a higher core count than Power9 processors, which allows for more parallel processing and improved performance.
- Improved memory bandwidth: Power10 processors have more memory bandwidth than Power9 processors, which allows for faster data transfer between the processor and memory. Enhanced security features: Power10 processors include enhanced security features, such as hardware-enforced memory encryption and real-time threat detection, to protect against cyber-attacks.
- Improved energy efficiency: Power10 processors are designed to be more energy efficient than Power9 processors, which can help to reduce power consumption and cooling costs. Optimized for AI workloads: Power10 processors are optimized for AI workloads and have better support for deep learning and other AI-related tasks.
- More flexible and open: Power10 architecture is more flexible and open. It supports more operating systems, and it has more open interfaces and more standard protocols to connect to other devices. Example: IBM Power Systems AC922.
- Natural Language Processing (NLP): This includes tasks such as speech recognition, text-to-speech, and machine translation.
- Computer Vision: This includes tasks such as image recognition, object detection, and facial recognition. Predictive analytics: This includes tasks such as forecasting, anomaly detection, and fraud detection.
- Robotics: This includes tasks such as navigation, object manipulation, and decision making. Recommender Systems: This includes tasks such as personalized product recommendations, content recommendations, and sentiment analysis.
- Generative Models: These include tasks such as image and video generation, text generation and music generation. Reinforcement learning: These include tasks such as game playing, decision making and control systems.
- Deep Learning: These include tasks such as Image and speech recognition, natural language processing and predictive analytics.